


There is one form of tree search which is especially economic: depth-first, left-to-right search by backtracking. It allows a search tree to be traversed systematically while requiring only a stack of maximum depth N for bookkeeping. Most other strategies of tree search (e.g. breadth-first) have exponential memory requirements. This unique property is the reason why backtracking is a built feature of ECLiPSe. Note that the main disadvantage of the depth-first strategy (the danger of going down an infinite branch) does not come into play here because we deal with finite search trees.
Sometimes depth-first search and heuristic search are treated as antonyms. This is only justified when the shape of the search tree is statically fixed. Our case is different: we have the freedom of deciding on the shape of every sub-tree before we start to traverse it depth-first. While this does not allow for absolutely any order of visiting the leaves of the search tree, it does provide considerable flexibility. This flexibility can be exploited by variable and value selection strategies.
In general, the nodes of a search tree represent choices. These choices should be mutually exclusive and therefore partition the search space into two or more disjoint sub-spaces. In other words, the original problem is reduced to a disjunction of simpler sub-problems.
In the case of finite-domain problems, the most common form of choice is to choose a particular value for a problem variable (this technique is often called labeling). For a boolean variable, this means setting the variable to 0 in one branch of the search tree and to 1 in the other. In ECLiPSe, this can be written as a disjunction (which is implemented by backtracking):
( X1=0 ; X1=1 )
Other forms of choices are possible. If X2 is a variable that can take
integer values from 0 to 3 (assume it has been declared as X2::0..3),
we can make a n-ary search tree node by writing
( X2=0 ; X2=1 ; X2=2 ; X2=3 )
or more compactly
indomain(X2)
However, choices do not necessarily involve choosing a concrete value for a variable. It is also possible to make disjoint choices by domain splitting, e.g.
( X2 #=< 1 ; X2 #>= 2 )
or by choosing a value in one branch and excluding it in the other:
( X2 = 0 ; X2 #>= 1 )
In the following examples, we will mainly use simple labeling, which means that the search tree nodes correspond to a variable and a node’s branches correspond to the different values that the variable can take.
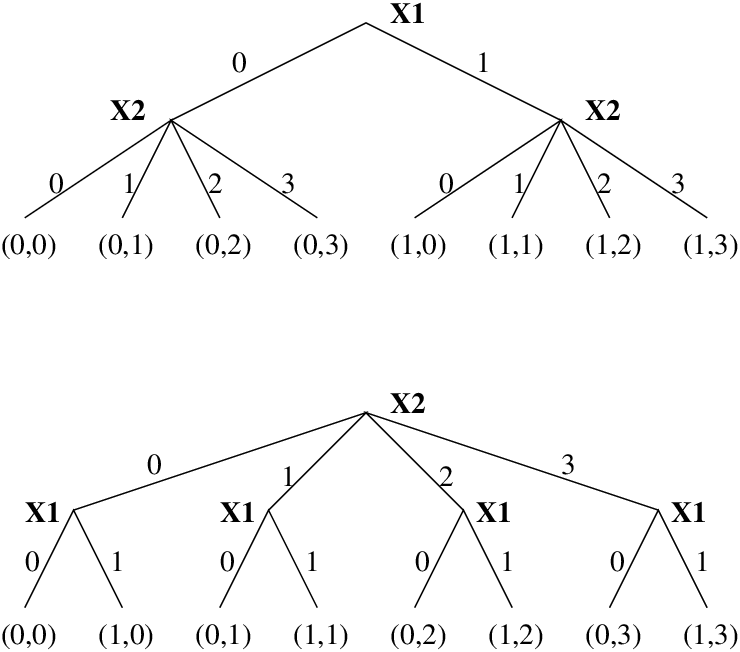
Figure 12.5: The effect of variable selection
Figure 12.5 shows how variable selection reshapes a search tree. If we decide to choose values for X1 first (at the root of the search tree) and values for X2 second, then the search tree has one particular shape. If we now assume a depth-first, left-to-right traversal by backtracking, this corresponds to one particular order of visiting the leaves of the tree: (0,0), (0,1), (0,2), (0,3), (1,0), (1,1), (1,2), (1,3).
If we decide to choose values for X2 first and X1 second, then the tree and consequently the order of visiting the leaves is different: (0,0), (1,0), (0,1), (1,1), (0,2), (1,2), (0,3), (1,3).
While with 2 variables there are only 2 variable selection strategies, this number grows exponentially with the number of variables. For 5 variables there are already 225−1 = 2147483648 different variable selection strategies to choose from.
Note that the example shows something else: If the domains of the variables are different, then the variable selection can change the number of internal nodes in the tree (but not the number of leaves). To keep the number of nodes down, variables with small domains should be selected first.
The other way to change the search tree is value selection, i.e. reordering the child nodes of a node by choosing the values from the domain of a variable in a particular order. Figure 12.6 shows how this can change the order of visiting the leaves: (1,2), (1,1), (1,0), (1,3), (0,1), (0,3), (0,0), (0,2).
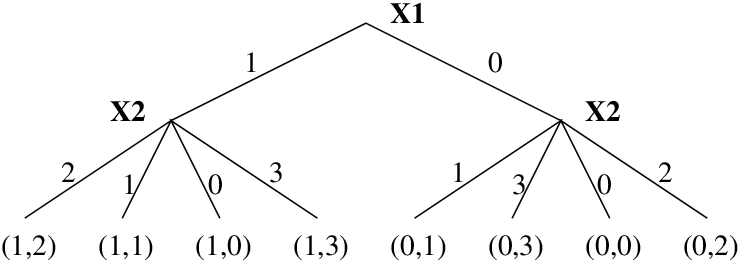
Figure 12.6: The effect of value selection
By combining variable and value selection alone, a large number of different heuristics can be implemented. To give an idea of the numbers involved, table 12.7 shows the search space sizes, the number of possible search space traversal orderings, and the number of orderings that can be obtained by variable and value selection (assuming domain size 2).
Variables Search space Visiting orders Selection Strategies 1 2 2 2 2 4 24 16 3 8 40320 336 4 16 2.1*1013 1.8*107 5 32 2.6*1035 3.5*1015 n 2n 2n! 22n−1 ∏i=0n−1 (n−1)2i
Figure 12.7: Flexibility of Variable/Value Selection Strategies
We use the famous N-Queens problem to illustrate how heuristics can be applied to backtrack search through variable and value selection. We model the problem with one variable per queen, assuming that each queen occupies one colunm. The variables range from 1 to N and indicate the row in which the queen is being placed. The constraints ensure that no two queens occupy the same row or diagonal:
|
We are looking for a first solution to the 16-queens problem by calling
?- queens(16, Vars), % model labeling(Vars). % search
We start naively, using the pre-defined labeling-predicate that comes with the ic library. It is defined as follows:
|
The strategy here is simply to select the variables from left to right as they occur in the list, and they are assigned values starting from the lowest to the numerically highest they can take (this is the definition of indomain/1). A solution is found after 542 backtracks (see section 12.2.5 below for how to count backtracks).
A first improvement is to employ a general-purpose variable-selection heuristic, the so called first-fail principle. It requires to label the variables with the smallest domain first. This reduces the branching factor at the root of the search tree and the total number of internal nodes. The delete/5 predicate from the ic_search library implements this strategy for finite integer domains. Using delete/5, we can redefine our labeling-routine as follows:
|
Indeed, for the 16-queens example, this leads to a dramatic improvement, the first solution is found with only 3 backtracks now. But caution is necessary: The 256-queens instance for example solves nicely with the naive strategy, but our improvement leads to a disappointment: the time increases dramatically! This is not uncommmon with heuristics: one has to keep in mind that the search space is not reduced, just re-shaped. Heuristics that yield good results with some problems can be useless or counter-productive with others. Even different instances of the same problem can exhibit widely different characteristics.
Let us try to employ a problem-specific heuristic: Chess players know that pieces in the middle of the board are more useful because they can attack more fields. We could therefore start placing queens in the middle of the board to reduce the number of unattacked fields earlier. We can achieve that simply by pre-ordering the variables such that the middle ones are first in the list:
|
The implementation of middle_first/2 requries a bit of list manipulation and uses primitives from the lists-library:
|
This strategy also improves things for the 16-queens instance, the first solution requires 17 backtracks.
We can now improve things further by combining the two variable-selection strategies: When we pre-order the variables such that the middle ones are first, the delete/5 predicate will prefer middle variables when several have the same domain size:
|
The result is positive: for the 16-queens instance, the number of backtracks goes down to zero, and more difficult instances become solvable!
Actually, we have not yet implemented our intuitive heuristics properly. We start placing queens in the middle columns, but not on the middle rows. With our model, that can only be achieved by changing the value selection, ie. setting the variables to values in the middle of their domain first. For this we can use indomain/2, a more flexible variant of indomain/1, provided by the ic_search library. It allows us to specify that we want to start labeling with the middle value in the domain:
|
Surprisingly, this improvement again increases the backtrack count for 16-queens again to 3. However, when looking at a number of different instances of the problem, we can observe that the overall behaviour has improved and the performance has become more predictable than with the initial more naive strategies. Figure 12.2.4 shows the behaviour of the different strategies on various problem sizes.
N = 8 12 14 16 32 64 128 256 labeling_a 10 15 103 542 labeling_b 10 16 11 3 4 148 labeling_c 0 3 22 17 labeling_d 0 0 1 0 1 1 labeling_e 3 3 38 3 7 1 0 0
Figure 12.8: N-Queens with different labeling strategies: Number of backtracks
An interesting piece of information during program development is the number of backtracks. It is a good measure for the quality of both constraint propagation and search heuristics. We can instrument our labeling routine as follows:
|
The backtrack counter itself can be implemented by the code below. It uses a non-logical counter variable (backtracks) and an additional flag (deep_fail) which ensures that backtracking to exhausted choices does not increment the count.
|
Note that there are other possible ways of defining the number of backtracks. However, the one suggested here has the following useful properties:
The search/6 predicates from the libary ic_search have this backtrack counter built-in.