In this chapter we discuss some high-level design decisions which should be clarified before starting the actual development of any code.
We first review the overall application structure found in systems developed at Parc Technologies (at least those using ECLiPSe for part of their development). We distinguish between two application types, one a full application with user-interface, database, reporting, etc, and the other a much smaller system, typically reading data from and to files and performing a single, batch type operation.
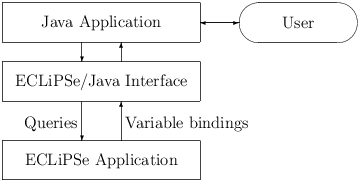
Figure 2.1: Full application
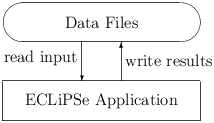
Figure 2.2: Batch type application
Examples of the first type (see figure 2.1) are Parc Technologies applications (http://www.parc-technologies.com) like AirPlanner and RiskWise1, where everything except the problem solver is developed in Java or related tools. The interface between the main application and the problem solver written in ECLiPSe is via a Java-ECLiPSe interface. In this interface, the main application poses queries for the ECLiPSe solver, passing data and arguments into ECLiPSe. The problem solver then runs the query and returns results as variable bindings in the given query. The Java side only knows about these queries, their data format and the expected results. The internals of the solver, how the queries are resolved, is completely hidden. This defines a nice interface between the application parts, as long as the queries are well defined and documented. Once that design is frozen, the developers for the different parts can continue development independently from each other, using stubs or dummy routines to simulate the other application parts.
The NDI-Mapper in RiskWise is an example of the second application type (see figure 2.2). The application reads some data files (defined in a clear specification), performs some operation on the data and produces results in another set of data files. The top-level query typically just states where the data should be found and where the results should be written to. This batch command then internally calls more detailed routines to load data, etc.
For each required function of the interface, we should define a specific query. The query consists of three parts. The first is the predicate name, which obviously should have a relation to the intended function. The second part consists of the input arguments, which are used to pass information from the outside to the problem solver. The structure of these arguments should be as simple as possible, easy to generate and to analyze. The third part consists of the output arguments, which are used to pass information from the problem solver back to the calling interface. When calling the query these arguments will be free variables, which are instantiated inside the solver to some result data structure.
The critical issue in defining the queries lies in identifying which data are required and/or produced, without building an actual implementation of the system. Another issue is the format of the data, which should allow a simple and efficient implementation without extra overhead for data manipulation. It is most important to get this interface right from the start, as any change will create re-work and problems integrating different versions of the software.
The API (application programmer’s interface) definition should be finished and signed-off by the designers of the main application and of the problem solver before any code is written2. The syntax of each query (predicate) should be defined completely, stating the argument structure and types for both input and outputs. A mode declaration should be used to indicate input and output arguments.
An important part of the API definition is the identification of constraints attached to the data. Constraints in this context are conditions that the data must satisfy in order to obtain meaningful results. These constraints ensure that the data set is complete, minimal and consistent.
Any constraints identified should be added to the specification of a data record in a numbered list, so that they can be identified easily. The example below shows the constraints attached to the
backbone_line(Node1, Interface1, Node2, Interface2)
structure in RiskWise.
For major application interfaces, in particular those linking the Java and the ECLiPSe side, it is recommended to write specific code checking the data for compliance with the constraints. This simplifies the integration task by either pointing out which data do not satisfy the constraints and are therefore invalid, or by guaranteeing that the data passed are correct, and any problem is on the receiving side of the interface.
At this point it is also a good idea to write some dummy batch tests which create the proper interface structures to test the queries. These dummy tests must satisfy the constraints on the data, but do not need to contain useful data. They will be used to exercise the interface and the data constraint checks for coverage with consistent data while integration testing is not yet possible.
Once the external API is clearly defined, we can start looking at the next level of internal structure. This will depend on the intended purpose of the system, but we can identify some typical structures that can be found in many applications. Here, we present two typical designs, one for solving combinatorial problems, the other for transforming data.
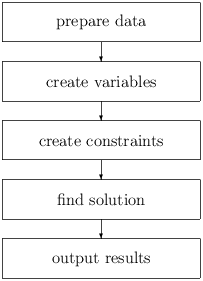
This structure is typical for large scale combinatorial optimization (LSCO) problems. The flow analysis part of RiskWise follows this structure. It consists of five parts, where each performs one particular task.
Figure 2.3: LCSO Application structure
It may not be immediately obvious, but it is very important to clearly separate the different phases. For example, it sometimes may seem faster to generate some variables together with the constraints that are set up between them, as this will save at least one scan of the data structure. But at the same time it makes it much more difficult to disable this constraint or to rearrange the constraints in a different order.
Exceptions to this rule are auxiliary variables which are only introduced to express some constraint and which are not part of the problem variables proper, or constraints that are introduced inside the search process in order to find a solution.
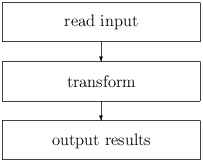
The second high-level design is a data transformation structure, used for example in the NDI-Mapper application. It consists of three parts.
Figure 2.4: Data transformation structure
The main limitation of this approach is that all data must be loaded into the application (in main memory). This limits the size of the data sets that can be handled to several megabytes. On the other hand, all information can be made available in an efficient way using lookup hash tables or arrays, so that the implementation of the transformation is quite simple.
Once we have decided on a top-level structure, we must consider the input/output arguments of each part. We have to decide which data must be fed into which modules, where new data structures will be created and which other modules require this data. For each piece of information we must identify its source and its possible sinks. Designing these data flows is an iterative process, assigning functionality to modules and making sure that the required information is available. The design aim should be to minimize the amount of information that must be passed across module boundaries and to arrange functions in the correct data flow order, so that all information is produced before it is required in another module.
It can be helpful to draw a data flow graph of the system as a directed graph, showing the main components as nodes and links between sources and sinks of information. A graph of this form should not contain any cycles, and if many links exist between two nodes, we may have to reconsider the split of functionality between.
We now have an idea of the overall structure of our application and can now turn this into the top-level code structure. We use the module concept of ECLiPSe to clearly separate the components and to define fixed interfaces between them. Each component of our top-level structure should define a module in one file. We place a module directive at the beginning of the file to indicate the module name.
The following examples are taken from the file flow_prepare_data.ecl.
:-module(flow_prepare_data).
The export directive makes some predicate definition available to users outside the module. All other predicates can be only used inside the module, but cannot be used from outside. A module effectively hides all non exported predicates in a separate name space, so that we do not have to worry about using the same name in two different modules.
In our example, the module exports a single predicate prepare_data/12.
:-export(prepare_data/12).
If we want to use some function which has been exported from some module in another module, we have to use the use_module directive. It says that all exported predicates of a module should be available in the current module, and ensures that the module is loaded into the system. We can use the same module in more than one place, but the directive makes sure it is loaded only once. The use_module directive assumes that the module is defined in a file in the current directory, which has the same name as the module.
The flow_prepare_data module uses predicates from a variety of sources.
:-use_module(data_topology). :-use_module(data_peering_policy). :-use_module(data_traffic). :-use_module(data_routing). :-use_module(data_group). :-use_module(data_general). :-use_module(flow_statistics). :-use_module(flow_structures). :-use_module(flow_utility). :-use_module(report). :-use_module(report_utility). :-use_module(utility).
If we want to use predicates defined in some library, we have to use the lib directive. It loads the library from the library directory in the ECLiPSe installation, unless we have changed the library path setting to include other directories in the search path. Libraries in ECLiPSe are modules like all others, they are just stored in a different place in the file system.
In our example, a single library called “hash” is loaded.
:-lib(hash).
We now introduce a naming scheme that should be used to define identifiers for the various entities in an ECLiPSe program. A consistent naming scheme makes it easier to maintain and modify the program, and also makes sure that contributions from different programmers can be merged without extra work. The scheme presented here is used for RiskWise.
Each module must have a unique name of the form [a-z][a-z_]+ . There is a one-to-one correspondence of modules and program files.
All program files in an application should be placed in a single directory, with each file named after the module it contains. The extension for ECLiPSe programs is .ecl.
Predicate names are of form [a-z][a-z_]*[0-9]* . Underscores are used to separate words. Digits should only be used at the end of the name. Words should be English. The top-level query of an application should be named top, and should execute a default query with some valid data set. Although predicates in different modules can use the same name, this can be confusing and should be avoided. You should also avoid using the same predicate name with different arity. Although legal, this can create problems when modifying code.
Variable names are of form [A-Z_][a-zA-Z]*[0-9]* . Separate words start with capital letters. Digits should only be used at the end. Words should be English. If a variable occurs only once in a clause, then its name should start with an underscore. This marks it as a singleton variable, and stops compiler warnings about the single occurrence of a variable. If a variable occurs more than once in a clause, then its name should not start with an underscore.
A program that is not documented is not usable. It is very hard to deduce the intention of a program piece just from the implementation, but even a few sentences of explanation can simplify this task dramatically. On the other hand, it is imperative that the documentation and the implementation are consistent. In ECLiPSe we use in-line comment directives to integrate the documentation with the program code. This makes it much easier to keep the documentation up to date than with a separate description file.
The comment directives are placed in the source code together with other parts of the program. The ECLiPSe system contains some library predicates which extract the comment directives and build a set of interrelated HTML pages for the documentation. The same system is used to generate the reference manual documentation of the library predicates. The comment directives come in two flavours. One is a comment for a module, which gives an overview what is module is for. As an example we again use the file flow_prepare_data.ecl.
:-comment(summary,"This file contains the data preparation for
the flow analysis.").
:-comment(desc,html("This file contains the data preparation for
the flow analysis.
")).
:-comment(author,"R. Rodosek, H. Simonis").
:-comment(copyright,"Parc Technologies Ltd").
:-comment(date,"$Date: 2017/10/25 10:03:20 $").
The other form of the comment directive is the predicate comment, which describes a particular predicate.
:-comment(prepare_data/12,[
summary:"creates the data structures for the flow analysis
",
amode:prepare_data(+,+,+,-,-,-,-,-,-,+,-,-),
args:[
"Dir":"directory for report output",
"Type":"the type of report to be generated",
"Summary":"a summary term",
"Nodes":"a nodes data structure",
"Interfaces":"a interfaces data structure",
"Lines":"a lines data structure",
"Groups":"a groups data structure",
"CMatrix":"a matrix (indexed by nodes) of contributions to
traffic",
"FMatrix":"a matrix (indexed by nodes) of flow variables",
"ScaleFactor":"the scale factor applied to the traffic data",
"Sizes":"the sizes of min, small, large, max packets",
"PMatrix":"The Pi Matrix containing the next hop information,
indexed by node keys"
],
desc:html("
This route creates the data structures for the flow analysis.
...
"),
see_also:[hop/3]
]).
The exact form of the different fields is described in the the documentation of the directives section of the ECLiPSe built-in predicate documentation in the ECLiPSe reference manual.
Many predicates in a module only perform very simple tasks which are immediately obvious from the implementation. It would be overkill to document all these predicates. We are working with a rule that all module interfaces must be documented, as well as all predicates which either have a complex implementation or which are expected to be customized by the user.
For predicates without a comment directive, we should use a one line description by a normal ECLiPSe comment in the source code.
We also use mode declarations to document the calling pattern of predicates. This uses four symbols
While the compiler uses the mode declarations for code optimization, we basically only use it to document the calling pattern. It allows to isolate a predicate definition and to understand its purpose without checking all callers3.
To continue with our example module flow_prepare_data, the one exported predicate has the following mode declaration4.
:-mode prepare_data(+,+,+,-,-,-,-,-,-,+,-,-).
If a system contains many modules, it can be helpful to provide a query which automatically generates the documentation for all files. In RiskWise, there is a module document with an entry point document/0 which creates the complete documentation tree. It uses the built-in predicates icompile/1 and ecis_to_htlms/4 to extract the documentation information from the source files and to build the HTML files required. Whenever we add a new module to the source of the application, we have to add its name into the components list.
document:-
components(L),
(foreach(Module,L) do
icompile(Module)
),
getcwd(Dir),
ecis_to_htmls([Dir],'HTML Doc',[],'ApplicationName').
components([
module1,
module2,
...
modulen]).