


Name conflicts occur in two flavours:
- Import/Import conflict:
- this is the case when two or more imported modules provide a predicate of the same name.
- Import/Local conflict:
- this is the case when a local (or exported) predicate has the same name as a predicate provided from an imported module.
Conflicts of the first type are accepted silently by the system as long as there is no reference to the conflict predicate. Only when an attempt is made to access the conflict predicate is an error raised. The conflict can be resolved by explicitly importing one of the versions, e.g.,
:- lib(ria). % exports #>= / 2 :- lib(eplex). % exports #>= / 2 :- import (#>=)/2 from ria. % resolves the conflict
Alternatively, the conflict can remain unresolved and qualified access can be used whenever the predicates are referred to (see 8.3.2).
Conflicts of the second type give rise to an error or warning message when the compiler encounters the local (re)definition. To avoid that, an explicit local/1 declaration has to be used:
:- local write/1. write(X) :- % my own version of write/1 ...
Note that the local/1-declaration must occur textually before any use of the predicate inside the module.
Normally, it is convenient to import predicates which are needed. By importing, they become visible and can be used within the module in the same way as local definitions. However, sometimes it is preferable to explicitly specify from which module a definition is meant to be taken. This is the case for example when multiple versions of the predicate are needed, or when the presence of a local definition makes it impossible to import a predicate of the same name from elsewhere. A call with explicit module qualification is done using :/2 and looks like this:
lists:print_list([1,2,3])
Here, the module where the definition of print_list/1 is looked up (the lookup module) is explicitly specified. To call print_list/1 like this, it is not necessary to make print_list/1 visible. The only requirement is that it is exported (or reexported) from the module lists.
Note that, if the called predicate is in operator notation, it will often be necessary to use brackets, e.g., in
..., ria:(X #>= Y), ...
The :/2 primitive can be used to resolve import conflicts, i.e., the case where the same name is exported from more than one module and both are needed. In this case, none of the conflicting predicates is imported - an attempt to call the unqualified predicate raises an error. The solution is to qualify every reference with the module name:
:- lib(ria). % exports #>= / 2 :- lib(eplex). % exports #>= / 2 ..., ria:(X #>= Y), ... ..., eplex:(X #>= Y), ...
Another case is the situation that a module wants to define a predicate of a given name but at the same time use a predicate of the same name from another module. It is not possible to import the predicate because of the name conflict with the local definition. Explicit qualification must be used instead:
:- lib(lists).
print_list(List) :-
writeln("This is the list"),
lists:print_list(List).
A more unusual feature, which is however very appropriate for constraint programming, is the possibility to call several versions of the same predicate by specifying several lookup modules:
..., [ria,eplex]:(X #>= Y), ...
which has exactly the same meaning as
..., ria:(X #>= Y), eplex:(X #>= Y), ...
Note that the modules do not have to be known at compile time, i.e., it is allowed to write code like
after(X, Y, Solver) :-
Solver:(X #>= Y).
However, this is likely to be less efficient because it prevents compile-time optimizations.
To allow more flexibility in the design of module interfaces, and to avoid duplication of definitions, it is possible to re-export definitions. A reexport is an import combined with an export. That means that a reexported definition becomes visible inside the reexporting module and is at the same time exported again. The only difference between exported and reexported definitions is that reexported predicates retain their original definition module.
There are 3 forms of the reexport/1 directive. To reexport the complete module interface of another module, use
:- reexport amodule.
To reexport only an explicitly enumerated selection, use
:- reexport p/1,q/2 from amodule.
To reexport everything except some explicitly enumerated items, use
:- reexport amodule except p/2,q/3.
These facilities make it possible to extend, modify, restrict or combine modules into new modules, as illustrated in figure 8.1.
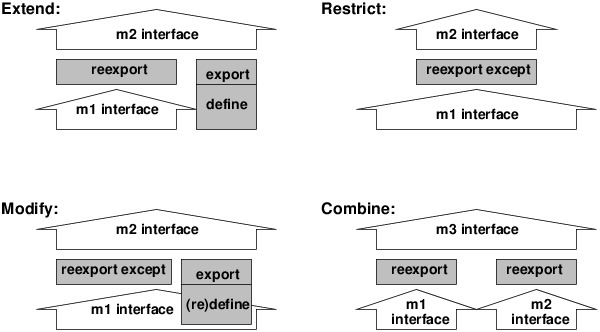
Figure 8.1: Making modules from modules with reexport
When a source file contains no module directives, it becomes part of the module from which its compilation was invoked. This makes it possible to write small programs without caring about modules. However, serious applications should be structured into modules.
Often it is the most appropriate to have one file per module and to have the file name match the module name.
It is however possible to have several modules in one file, e.g., a main module and one or more auxiliary modules - in that case the name of the main module should match the file name. Every module-directive in the file marks the end of the previous module and the start of the next one.
It is also possible to spread the contents of a module over several files. In this case, there should be a main file whose file name matches the module name, and the other files should be referenced from the main file using the include/1 directive, e.g.,
:- module(bigmodule). :- include(part1). :- include(part2).
There are predicates in a modular system that must be able to determine from which module they were called (since this may be different from the module in which they were defined). The most common case is where a predicate is a meta-predicate, i.e., a predicate that has another goal or predicate name as an argument. Other cases are I/O predicates—they must be executed in a certain module context in order to obey the correct syntax of this module. In ECLiPSe, predicates that must be able to determine their context module are called tool predicates.2
Tool predicates must be declared. As a consequence, the system will automatically add a context module argument whenever such a tool predicate is called.
Consider for example a predicate that calls another predicate twice. The naive version of this predicate looks like
twice(Goal) :-
call(Goal),
call(Goal).
As long as no modules are involved, this works fine. Now consider the situation where the definition of twice/1 and a call of twice/1 are in two different modules:
:- module(stuff).
:- export twice/1.
twice(Goal) :-
call(Goal),
call(Goal).
:- module(main).
:- import stuff.
top :- twice(hello).
hello :- writeln(hi).
This will not work because hello/0 is only visible in module main and an attempt to call it from within twice/1 in module stuff will raise an error. The solution is to declare twice/1 as a tool and change the code as follows:
:- module(stuff).
:- export twice/1.
:- tool(twice/1, twice/2).
twice(Goal, Module) :-
call(Goal)@Module,
call(Goal)@Module.
What happens now is that the call to twice/1 in module main
..., twice(hello), ...
is effectively replaced by the system with a call to twice/2 where the additional argument is the module in which the call occurs:
..., twice(hello, main), ...
This context module is then used by twice/2 to execute
..., call(hello)@main, ...
The call(Goal)@Module construct means that the call is supposed to happen in the context of module main.
The debugger trace shows what happens:
[main 5]: top. (1) 1 CALL top (2) 2 CALL twice(hello) (3) 3 CALL twice(hello, main) (4) 4 CALL call(hello) @ main (5) 5 CALL call(hello) (6) 6 CALL hello S (7) 7 CALL writeln(hi) hi S (7) 7 EXIT writeln(hi) (6) 6 EXIT hello ...
One complication that can arise when you use tools is that the compiler must know that a predicate is a tool in order to properly compile a call to the tool. If the call occurs textually before the tool declaration, this will therefore give rise to an inconsistent tool redefinition error. The tool/2 declaration must therefore occur before any call to the tool.
Many of the system built-in predicates are in fact tools, e.g., read/1, write/1, record/2, compile/1, etc. All predicates which handle modular items must be tools so that they know from which module they have been called. In case that the built-in predicate has to be executed in a different module (this is very often the case inside user tool predicates), the @/2 construct must be used, e.g.,
current_predicate(P) @ SomeModule
The following table summarises the different call patterns with and without module specifications. There are only two basic rules to remember:
| Call inside module (m) | Module where definition of twice/1 is looked up | Context module argument added to twice/1 |
| ..., twice(X), ... | m | m |
| ..., lm : twice(X), ... | lm | m |
| ..., twice(X) @ cm, ... | m | cm |
| ..., lm : twice(X) @ cm, ... | lm | cm |
| ..., call(twice(X)) @ cm, ... | cm | cm |
The primitive current_module/1 can be used to check for the existence of a module, or to enumerate all currently defined modules.
Further details about existing modules can be retrieved using get_module_info/3, in particular information about the module’s interface, what other modules it uses and whether it is locked (see 8.4.4).
Information about a predicate’s properties can be retrieved using the get_flag/3 primitive or printed using pred/1. The module-related predicate properties are:
- defined
- (on/off) indicates whether code for the predicate has already been compiled. If not, only a declaration was encountered.
- definition_module
- (an atom) the module where the predicate is defined.
- visibility
- (local/exported/reexported/imported) indicates the visibility of the predicate in the context module.
- tool
- (on/off) indicates whether the predicate has been declared a tool.
For tool predicates, tool_body/3 can be used to retrieve the predicate it maps to when the module argument is added.
To get information about a predicate visible in a different module, use for instance
get_flag(p/3, visibility, V) @ othermodule