


The library ic_search contains a flexible search routine search/6, which implements several variants of incomplete tree search.
For demonstration, we will use the N-queens problem from above. The following use of search/6 is equivalent to labeling(Xs) and will print all 92 solutions:
?- queens(8, Xs),
search(Xs, 0, input_order, indomain, complete, []),
writeln(Xs),
fail.
[1, 5, 8, 6, 3, 7, 2, 4]
...
[8, 4, 1, 3, 6, 2, 7, 5]
No.
One of the easiest ways to do incomplete search is to simply stop after the first solution has been found. This is simply programmed using cut or once/1:
?- queens(8, Xs),
once search(Xs, 0, input_order, indomain, complete, []),
writeln(Xs),
fail.
[1, 5, 8, 6, 3, 7, 2, 4]
No.
This will of course not speed up the finding of the first solution.
Another way to limit the scope of backtrack search is to keep a record of the number of backtracks, and curtail the search when this limit is exceeded.
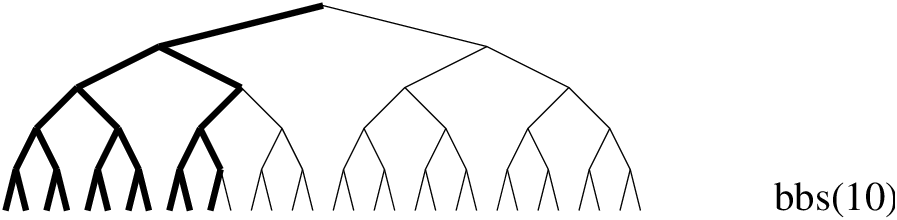
Figure 12.9: Bounded-backtrack search
The bbs option of the search/6 predicate implements this:
?- queens(8, Xs),
search(Xs, 0, input_order, indomain, bbs(20), []),
writeln(Xs),
fail.
[1, 5, 8, 6, 3, 7, 2, 4]
[1, 6, 8, 3, 7, 4, 2, 5]
[1, 7, 4, 6, 8, 2, 5, 3]
[1, 7, 5, 8, 2, 4, 6, 3]
No.
Only the first 4 solutions are found, the next solution would have required more backtracks than were allowed. Note that the solutions that are found are all located on the left hand side of the search tree. This often makes sense because with a good search heuristic, the solutions tend to be towards the left hand side. Figure 12.9 illustrates the effect of bbs (note that the diagram does not correspond to the queens example, it shows an unconstrained search tree with 5 binary variables).
A simple method of limiting search is to limit the depth of the search tree. In many constraint problems with a fixed number of variables this is not very useful, since all solutions occur at the same depth of the tree. However, one may want to explore the tree completely up to a certain depth and switch to an incomplete search method below this depth. The search/6 predicate allows for instance the combination of depth-bounded search with bounded-backtrack search. The following explores the first 2 levels of the search tree completely, and does not allow any backtracking below this level.
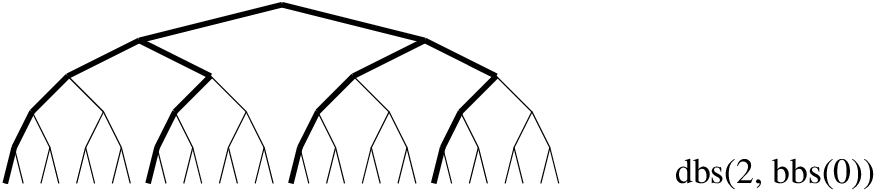
Figure 12.10: Depth-bounded, combined with bounded-backtrack search
This gives 16 solutions, equally distributed over the search tree:
?- queens(8, Xs),
search(Xs, 0, input_order, indomain, dbs(2,bbs(0)), []),
writeln(Xs),
fail.
[3, 5, 2, 8, 1, 7, 4, 6]
[3, 6, 2, 5, 8, 1, 7, 4]
[4, 2, 5, 8, 6, 1, 3, 7]
[4, 7, 1, 8, 5, 2, 6, 3]
[4, 8, 1, 3, 6, 2, 7, 5]
[5, 1, 4, 6, 8, 2, 7, 3]
[5, 2, 4, 6, 8, 3, 1, 7]
[5, 3, 1, 6, 8, 2, 4, 7]
[5, 7, 1, 3, 8, 6, 4, 2]
[6, 4, 1, 5, 8, 2, 7, 3]
[7, 1, 3, 8, 6, 4, 2, 5]
[7, 2, 4, 1, 8, 5, 3, 6]
[7, 3, 1, 6, 8, 5, 2, 4]
[8, 2, 4, 1, 7, 5, 3, 6]
[8, 3, 1, 6, 2, 5, 7, 4]
[8, 4, 1, 3, 6, 2, 7, 5]
No (0.18s cpu)
Credit search[1] is a tree search method where the number of nondeterministic choices is limited a priori. This is achieved by starting the search at the tree root with a certain integral amount of credit. This credit is split between the child nodes, their credit between their child nodes, and so on. A single unit of credit cannot be split any further: subtrees provided with only a single credit unit are not allowed any nondeterministics choices, only one path though these subtrees can be explored, i.e. only one leaf in the subtree can be visited. Subtrees for which no credit is left are pruned, i.e. not visited.
The following code (a replacement for labeling/1) implements credit search. For ease of understanding, it is limited to boolean variables:
|
Note that the leftmost alternative (here X=0) gets slightly more credit than the rightmost one (here X=1) by rounding the child node’s credit up rather than down. This is especially relevant when the leftover credit is down to 1: from then on, only the leftmost alternatives will be taken until a leaf of the search tree is reached. The leftmost alternative should therefore be the one favoured by the search heuristics.
What is a reasonable amount of credit to give to a search? In an unconstrained search tree, the credit is equivalent to the number of leaf nodes that will be reached. The number of leaf nodes grows exponentially with the number of labelled variables, while tractable computations should have polynomial runtimes. A good rule of thumb could therefore be to use as credit the number of variables squared or cubed, thus enforcing polynomial runtime.
Note that this method in its pure form allows choices only close to the root of the search tree, and disallows choices completely below a certain tree depth. This is too restrictive when the value selection strategy is not good enough. A possible remedy is to combine credit search with bounded backtrack search.
The implementation of credit search in the search/6 predicate works for arbitrary domain variables: Credit is distributed by giving half to the leftmost child node, half of the remaining credit to the second child node and so on. Any remaining credit after the last child node is lost.
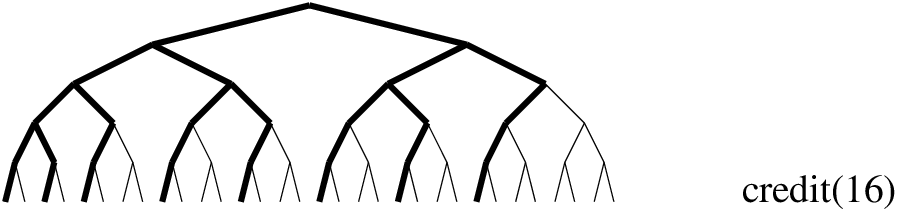
Figure 12.11: Credit-based incomplete search
In this implementation, credit search is always combined with another search method which is to be used when the credit runs out.
When we use credit search in the queens example, we get a limited number of solutions, but these solutions are not the leftmost ones (like with bounded-backtrack search), they are from different parts of the search tree, although biased towards the left:
?- queens(8, Xs), search(Xs, 0, input_order, indomain, credit(20,bbs(0)), []), writeln(Xs), fail. [2, 4, 6, 8, 3, 1, 7, 5] [2, 6, 1, 7, 4, 8, 3, 5] [3, 5, 2, 8, 1, 7, 4, 6] [5, 1, 4, 6, 8, 2, 7, 3] No.
We have used a credit limit of 20. When credit runs out, we switch to bounded backtrack search with a limit of 0 backtracks.
Another form of incomplete tree search is simply to use time-outs. The branch-and-bound primitives bb_min/3,6 allow a maximal runtime to be specified. If a timeout occurs, the best solution found so far is returned instead of the proven optimum.
A general timeout is available from the library test_util. It has parameters timeout(Goal, Seconds, TimeOutGoal). When Goal has run for more than Seconds seconds, it is aborted and TimeOutGoal is called instead.
Limited discrepancy search (LDS) is a search method that assumes the user has a good heuristic for directing the search. A perfect heuristic would, of course, not require any search. However most heuristics are occasionally misleading. Limited Discrepancy Search follows the heuristic on almost every decision. The “discrepancy” is a measure of the degree to which it fails to follow the heuristic. LDS starts searching with a discrepancy of 0 (which means it follows the heuristic exactly). Each time LDS fails to find a solution with a given discrepancy, the discrepancy is increased and search restarts. In theory the search is complete, as eventually the discrepancy will become large enough to admit a solution, or cover the whole search space. In practice, however, it is only beneficial to apply LDS with small discrepancies. Subsequently, if no solution is found, other search methods should be tried. The definitive reference to LDS is [29]
There are different possible ways of measuring discrepancies. The one implemented in the search/6 predicate is a variant of the original proposal. It considers the first value selection choice as the heuristically best value with discrepancy 0, the first alternative has a discrepancy of 1, the second a discrepancy of 2 and so on.
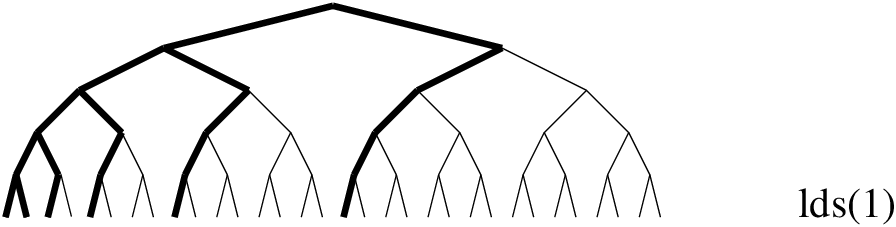
Figure 12.12: Incomplete search with LDS
As LDS relies on a good heuristic, it only makes sense for the queens problem if we use a good heuristic, e.g. first-fail variable selection and indomain-middle value selection. Allowing a discrepancy of 1 yields 4 solutions:
?- queens(8, Xs), search(Xs, 0, first_fail, indomain_middle, lds(1), []), writeln(Xs), fail. [4, 6, 1, 5, 2, 8, 3, 7] [4, 6, 8, 3, 1, 7, 5, 2] [4, 2, 7, 5, 1, 8, 6, 3] [5, 3, 1, 6, 8, 2, 4, 7] No.
The reference also suggests that combining LDS with Bounded Backtrack Search (BBS) yields good behaviour. The search/6 predicate accordingly supports the combination of LDS with BBS and DBS. The rationale for this is that heuristic choices typically get more reliable deeper down in the search tree.